HomeThis is the home page of the SPIRAL project. The goal of SPIRAL is to push the limits of automation in software and hardware development and optimization for digital signal processing (DSP) algorithms and other numerical kernels beyond what is possible with current tools. Our basic research question is Can we teach computers to write fast libraries? Our flagship is the SPIRAL program generation system, which, entirely autonomously, generates platform-tuned implementations of signal processing transform such as the discrete Fourier transform, discrete cosine transform, and many others. Look at a few benchmarks. But we also provide other online generators (see the right column). SPIRAL addresses one of the current key problems in numerical software and hardware development: how to achieve close to optimal performance with reasonable coding effort? (More detailed problem statement.) SPIRAL comprises an interdisciplinary team of researchers in the areas of signal processing, algorithms, scientific computing, compilers, computer architecture, and mathematics. In the domain of linear transform, and for standard multicore platforms (Core 2 Duo like), we have achieved complete automation: the computer generation of general input-size, vectorized, parallel libraries. Learn Quickly About SPIRALThis short article in the recent Encyclopedia of Parallel Computing describes the main ideas behind our program synthesis work for transforms:
Selected TalksF. FranchettiSPIRAL: AI for High Performance Code with a Side of FFTX Alphabet Inc., August 2021, virtual F. Franchetti SPIRAL: AI for High Performance Code Joint work with SPIRAL team at CMU and FFTX team at CMU and LBL Oak Ridge National Laboratory, October 2019 Good Choice for Citing SPIRAL (Overview Paper)
After this paper we started to attack all forms of parallel platforms and the generation of entire libraries like FFTW. A good reference for the last version of Spiral is the encyclopedia article above. Research Threads
ContactIf you have questions or comments about SPIRAL or our work in general, please send email to help (at) spiral.net.
|
Open Source SPIRAL SystemOpen Source SPIRAL is available here under non-viral license (BSD-style license). See the SPIRAL User Manual for more information. Please let us know which parts of SPIRAL you are most interested in. Commercial support is available via SpiralGen, Inc.
FFTX and SPIRALFFTX is the exascale follow-on to the FFTW open source discrete FFT package for executing the Fast Fourier Transform as well as higher-level operations composed of linear operations combined with DFT transforms. At the heart of FFTX is a build-time code generator, SPIRAL, that produces very high performance kernels targeted to their specific uses and platform environments. 
Online GeneratorsWe provide a number of online generators, which are easy and fun to use or play with.Online generators currently available
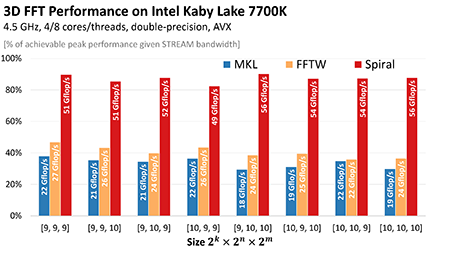
DFT = discrete Fourier transform, DCT = discrete cosine transform. Featured Result
References
|
|