
Viterbi Decoder Software Generator
What Is It?
The Spiral Viterbi Software Generator automatically generates high-performance software implementations for decoders for a large class of convolutional codes. The user specifies the code and the target architecture; the generator returns the source code (Intel compatible) for an encoder and a high-performance decoder using the Viterbi algorithm.
We reuse the infrastructure, the encoder, and the traceback of the decoder from Phil Karn's implementation (slightly modified). We only generated the (most costly) forward part of the Viterbi decoder.
If you are interested in a commercial license or other code for the physical layer of software defined radio standards, please contact SpiralGen.
Background
Convolutional codes [2] are a common type of error-correcting code where encoding is traditionally done in hardware using a shifting register and modulo-2 adders. Every cycle, a new value enters the register and the modulo-2 additions of some values inside the register constitute the output bits. The inverse of the number of adders describes the ratio of meaningful data within the message and is called the rate r of the code. The length of the shifting register constitutes the "memory" of the code and is called the constraint-length, usually denoted as K. The actual wiring of the adders are called the polynomials. There are as many polynomials as the inverse of the rate and each one is an integer between 1 and 2^K - 1. Because of the finiteness of K, the encoding operation can be equivalently represented as a finite state machine (FSM) with 2^(K-1) states.
The Viterbi algorithm [3,4] implements a maximum likelihood decoder: Given a corrupted encoded bitstream, its purpose is to return the most probable original data. Using a representation called the Viterbi trellis, the algorithm maintains the cost of being in every state of the FSM based on the Hamming distance to the message. It resolves conflicts locally during the forward pass and reads off results during the traceback.
Generator
Input: parameters specifying the convolutional code and the target architecture
Output: C code, or C code with Intel compatible SSE vector instructions, for a Viterbi decoder for the specified code. Longer vector length means higher performance (see benchmark below).
Thanks to Jon Hamkins (Jet Propulsion Laboratory, Pasadena) for alerting us to a few bugs in the code definitions and misnomers
Benchmarks
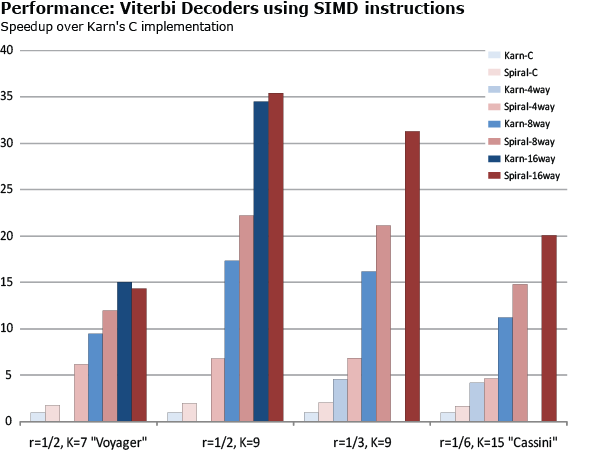
Below we benchmark our generated implementations of Viterbi decoding for four different convolutional codes and for different degrees of SIMD vectorization (scalar, 4-way, 8-way, 16-way) against Phil Karn's implementation. The base line is Karn's C code, which is normalized to 1. Higher is better. A missing bar means that the vector length is not provided by Karn (e.g., 4-way for the Voyager code).
Blue = Karn's implementations, red = Spiral-generated implementations, darker = longer vectors = higher performance
References
- Frédéric de Mesmay, Srinivas Chellappa, Franz Franchetti and Markus Püschel
Computer Generation of Efficient Software Viterbi Decoders
Proc. International Conference on High Performance Embedded Architectures and Compilers (HiPEAC), Lecture Notes in Computer Science, Springer, Vol. 5952, pp. 353-368, 2010 - W.W. Peterson and E.J. Weldon, Jr.
Error-Correcting Codes
2nd edition, MIT Press: Cambridge, Mass. - A. Viterbi
Error bounds for convolutional codes and an asymptotically optimum decoding algorithm
IEEE Trans. Inform. Theory, IT-13:260–269, Apr.1967 - G.D. Forney Jr.
The Viterbi algorithm
Proceedings of the IEEE, 61(3), March 1973 Page(s):268 - 278
Copyrights to many of the above papers are held by the publishers. The attached PDF files are preprints. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder. Some links to papers above connect to IEEE Xplore with permission from IEEE, and viewers must follow all of IEEE's copyright policies.
More Information
This generator is part of the Spiral library generation system and was created by Frédéric de Mesmay based on earlier work by Srinivas Chellappa.
For questions or comments please email help at spiral dot net.