
NTTX and SPIRAL
What is it?
NTTX is an FFTX-like package that leverages SPIRAL's capability of autonomous code generation and platform-based autotuning to generate high-performance code of Number Theoretic Transforms (NTTs), which are widely used to accelerate Fully Homomorphic Encryption (FHE), a post-quantum encryption scheme. Mirroring the structure of FFTW and FFTX, the NTTX package offers FFTW-style C/C++ API in line with FFTX-style code generation.
Overview
Fully Homomorphic Encryption (FHE) allows direct computation on sensitive information through mathematical transforms upon encrypted data. FHE uses lattice-based cryptography to encode vectors of numerical data onto mathematical structures (lattices and rings), thereby enabling a set of basic arithmetic operations to be performed while encrypted. These operations can be combined for applications like pattern matching, linear algebra, basic statistics, and machine learning.
To encode and operate on different types of data, several schemes have been proposed, including BGV, BFV, and CKKS. All these schemes are based on lattice cryptography, requiring a core set of mathematical operations in the form of integer modulo vector arithmetic. A major optimization for FHE schemes is using Number Theoretic Transform (NTT) to accelerate the computation of vector convolutions, similar to the fast Fourier Transform (FFT) in the signal processing domain. Akin to FFT, the need for automatic high-performance code generation and autotuning NTT is therefore imminent.
SPIRAL is a code generation system that takes in high-level mathematical abstractions and synthesizes highly-optimized implementations. Leveraging SPIRAL's capability of autonomous code generation and platform-based autotuning, we expand SPIRAL to the NTT domain based on prior work on FFTX and modular FFT. While the current prototype supports ANSI C, CUDA, and a specialized vector ISA, the code generation backend targets all SPIRAL-supported platforms.
Benchmarks
GPU
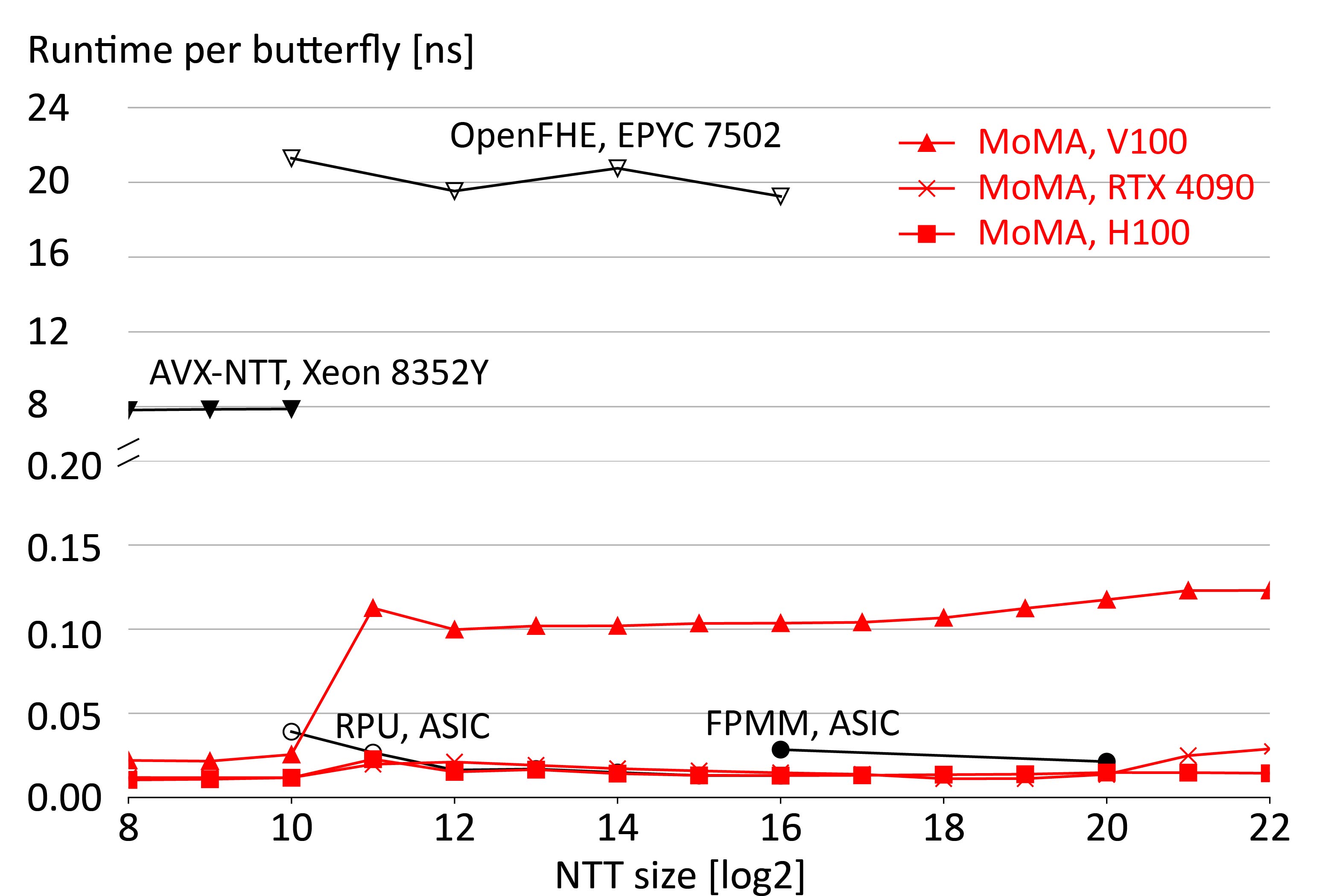
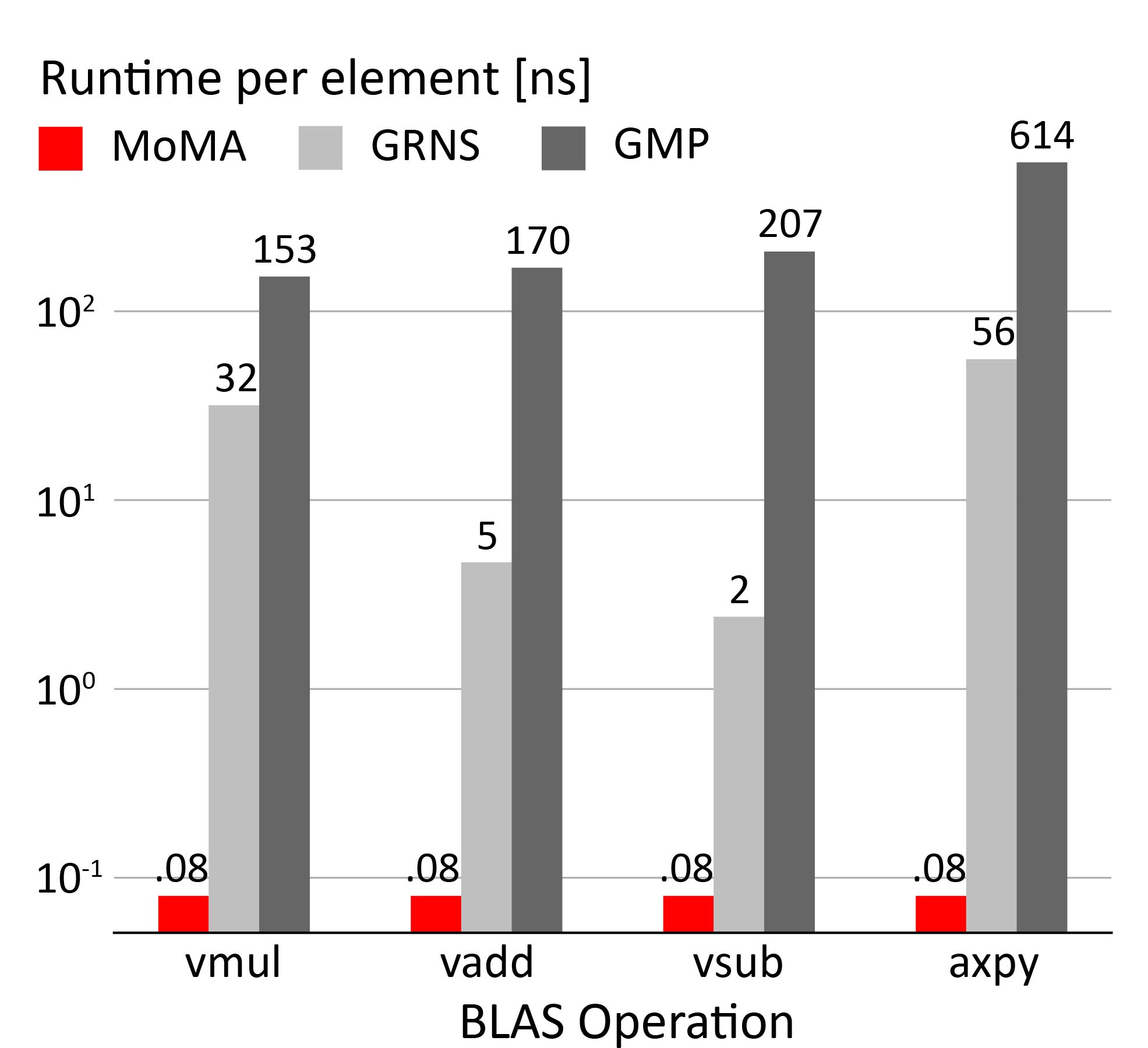
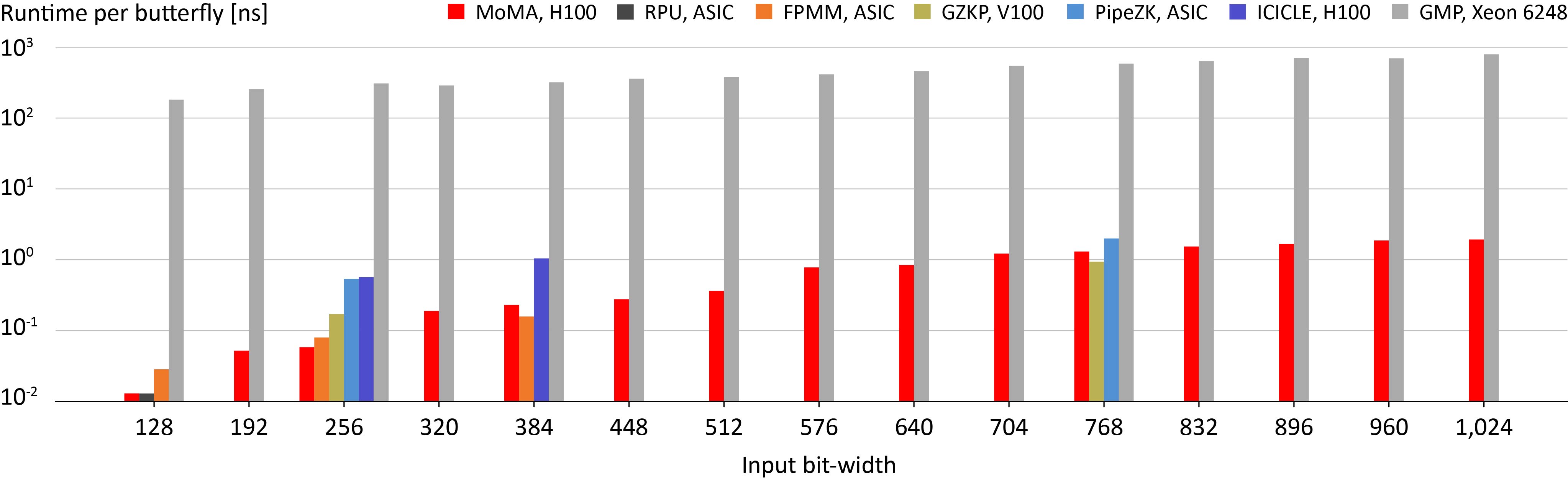
We benchmarked the performance of SPIRAL-generated cryptographic kernels across three types of GPUs from different hardware generations and price points: the NVIDIA H100 Tensor Core, the NVIDIA Tesla V100 Tensor Core and the NVIDIA GeForce RTX 4090.
Ring Processing Unit
The Ring Processing Unit (RPU) is a high-performance multi-tile architecture built specifically for FHE acceleration. A cycle-level performance and functional simulator was developed to study RPU and conduct design space exploration. It was written in C++ and models each aspect of the design, faithfully processing B512 code, the vector ISA supported by RPU, generated by SPIRAL. The simulator is configurable to consider different VDM banking strategies, allocations of HPLEs, pipeline depths, and component IP (e.g., multiplier).
 |
 |
 |
 |
Software Download
The software is provided as a repository on GitHub.
References
- N. Zhang, F. Franchetti
Code Generation for Cryptographic Kernels using Multi-wordModular Arithmetic on GPU
The International Symposium on Code Generation and Optimization (CGO), 2025 - S. Fu, N. Zhang, F. Franchetti
Accelerating High-Precision Number Theoretic Transforms using Intel AVX-512
International Conference on Parallel Architectures and Compilation Techniques (PACT), 2024, Poster with extended abstract
1st Place in ACM Student Research Competition
Best Poster Runner-up at PRISM Annual Review, Systems & Software track - Y. Eum, N. Zhang, L. Tang, F. Franchetti
Towards a RISC-V Instruction Set Extension for Multi-word Arithmetic
IEEE High Performance Extreme Computing Conference (HPEC), 2024, Poster with extended abstract - N. Zhang, A. Ebel, N. Neda, P. Brinich, B. Reynwar, A. G. Schmidt, M. Franusich, J. Johnson, B.
Reagen, F. Franchetti
Generating High-Performance Number Theoretic Transform Implementations for Vector Architectures
IEEE High Performance Extreme Computing Conference (HPEC), 2023 - P. Brinich, N. Zhang, A. Ebel, F. Franchetti, J. Johnson
Twiddle Factor Generation for a Vectorized Number Theoretic Transform
IEEE High Performance Extreme Computing Conference (HPEC), 2023, Extended abstract
Outstanding Short Paper Award - N. Zhang, F. Franchetti
Generating Number Theoretic Transforms for Multi-Word Integer Data Types
IEEE/ACM International Symposium on Code Generation and Optimization (CGO), 2023, Poster with extended abstract
2nd Place in ACM Student Research Competition - D. Soni, N. Neda, N. Zhang, B. Reynwar, B. Heyman, M. Nabeel, A. Al Badawi, Y. Polyakov, K. Canida, M. Pedram, M. Maniatakos, D. B. Cousins, F. Franchetti, M. French, A. G. Schmidt, B. Reagen
RPU: The Ring Processing Unit
IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2023 - D. B. Cousins, Y. Polyakov, A. Al Badawi, M. French, A. Schmidt, A. Jacob, B. Reynwar, K. Canida, A. Jaiswal, C. Mathew, H. Gamil, N. Neda, D. Soni, M. Maniatakos, B. Reagen, N. Zhang, F. Franchetti, P. Brinich, J. Johnson, P. Broderick, M. Franusich, B. Zhang, Z. Cheng, M. Pedram
TREBUCHET: Fully Homomorphic Encryption Accelerator for Deep Computation
arXiv, 2023, Preprint - N. Zhang, H. Gamil, P. Brinich, B. Reynwar, A. Al Badawi, N. Neda, D. Soni, K. Canida, Y. Polyakov, P. Broderick, M. Maniatakos, A. G. Schmidt, M. Franusich, J. Johnson, B. Reagen, D. B. Cousins, F. Franchetti
Towards Full-Stack Acceleration for Fully Homomorphic Encryption
IEEE High Performance Extreme Computing Conference (HPEC), 2022, Extended abstract - L. Meng, J. R. Johnson, F. Franchetti, Y. Voronenko, M. Moreno Maza, and Y. Xie
Spiral-Generated Modular FFT Algorithms
Proceedings 4th International Workshop on Parallel Symbolic Computation (PASCO), 2010, pages 169170
Copyrights to many of the above papers are held by the publishers. The attached PDF files are preprints. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder. Some links to papers above connect to IEEE Xplore with permission from IEEE, and viewers must follow all of IEEE's copyright policies.
More Information
Please email Naifeng Zhang at [naifengz at cmu dot edu] or visit Franz Franchettis projects page.